DeepSEE:
Deep Disentangled Semantic
Explorative Extreme
Super-Resolution
in ACCV 2020 (oral)

Abstract
Super-resolution (SR) is by definition ill-posed. There are infinitely many plausible high-resolution variants for a given low-resolution natural image. Most of the current literature aims at a single deterministic solution of either high reconstruction fidelity or photo-realistic perceptual quality. In this work, we propose an explorative facial super-resolution framework, DeepSEE, for Deep disentangled Semantic Explorative Extreme super-resolution. To the best of our knowledge, DeepSEE is the first method to leverage semantic maps for explorative super-resolution. In particular, it provides control of the semantic regions, their disentangled appearance and it allows a broad range of image manipulations. We validate DeepSEE on faces, for up to 32x magnification and exploration of the space of super-resolution.

Visual Results

Semantic Manipulations

Style Manipulations

Extreme Upscaling (32x)
Method
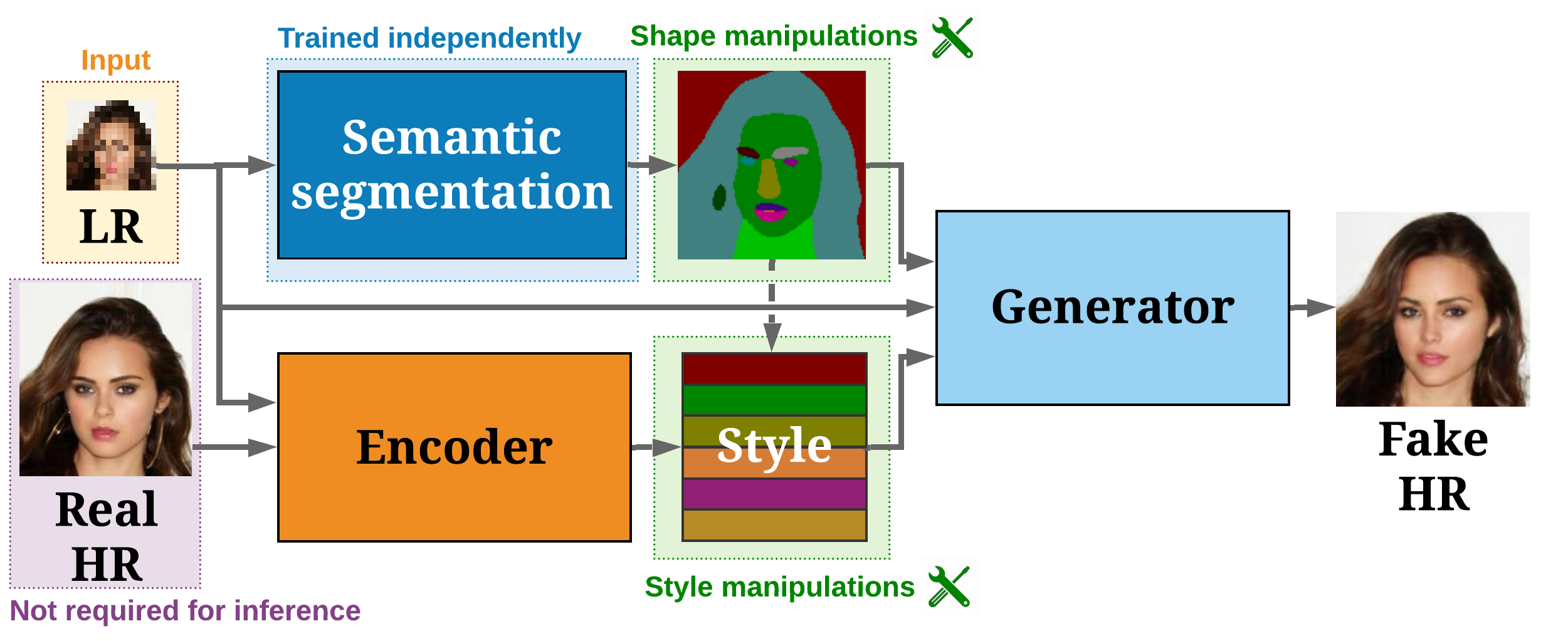
Our generator upscales low-resolution input (LR) conditioned on both a semantic layout and a style matrix. This allows to control the appearance, as well as the size and shape of each region in the semantic layout. By modifying these conditional inputs, DeepSEE can generate a multitude of potential solutions and explore the solution space.
Citation
Marcel Christoph Bühler, Andrés Romero, and Radu Timofte.
Deepsee: Deep disentangled semantic explorative extreme super-resolution.
In The 15th Asian Conference on Computer Vision (ACCV), 2020.
Bibtex
Acknowledgements
We would like to thank the Hasler Foundation. In addition, this work was partly supported by the ETH Zürich Fund (OK), a Huawei Technologies Oy (Finland) project, an Amazon AWS and an NVIDIA grant.